T-Rex: Tactile-ReactiveDexterous Manipulation
Abstract
The ability to react dynamically to tactile signals has long been considered crucial to agile, human-level dexterity. Yet contemporary learning-based Vision-Language-Action (VLA) models for robotic manipulation generally either overlook the tactile modality altogether or are limited to encoders that capture only static cues. This gap stems from three obstacles: the scarcity of diverse training data and standardized evaluation, architectural constraints in current VLA models, and the limitations of static tactile encoders. T-Rex pushes the frontier of tactile-reactive manipulation by addressing all three. We open-source a large-scale, 100-hour tactile-rich dataset collected via a novel, data-efficient recipe that prioritizes elementary motor primitives. To exploit naturally high-frequency touch signals without sacrificing the capabilities of existing VLAs, we introduce a variable-rate Mixture-of-Transformer (MoT) architecture equipped with a novel temporal tactile VQ-VAE encoder. We demonstrate the effectiveness of tactile-reactive policies on 12 manipulation tasks requiring delicate force control and deformable-object manipulation, achieving over 30% higher average success rate than the strongest baseline.
Contributions
T-Rex redesigns the full pipeline across data, architecture, and real-world tasks:
- The T-Rex Dataset — an open-source, 100-hour, tactile-synchronized teleoperation dataset organized around diverse object × motor-primitive combinations, filling the tactile gap in vision-only training data.
- A three-stage training paradigm — human egocentric pre-training, tactile-rich mid-training, and lightweight fine-tuning — the first complete recipe for tactile dexterous manipulation.
- The T-Rex Model — a variable-rate Mixture-of-Transformer that splits control into a low-rate action expert and a high-rate tactile expert providing reactive residual refinements.
- A temporal tactile VQ-VAE encoder that compresses high-frequency touch into compact, drift-robust tokens of temporal force and contact patterns.
- A 12-task real-world benchmark on a 58-DoF bimanual dexterous robot, spanning force control, deformation, and bimanual coordination — and state-of-the-art results, beating the strongest baseline by over 30% average success rate.
The T-Rex Dataset
Most robot-manipulation datasets are built around parallel grippers or grasp-centric hands, offering limited coverage of tactile-rich interactions. The T-Rex Dataset is a large-scale, tactile-synchronized robot “play” corpus for mid-training. Rather than chasing a few long tasks, it follows a deliberately data-efficient recipe that prioritizes broad coverage of elementary motor primitives — short, reusable contact-rich behaviors that compose into complex skills. Every episode is structured around an object × motor-primitive combination: pairing 207 household objects with 22 motor primitives and pruning the physically infeasible pairs yields 502 unique, meaningful combinations, each with ~17 demonstrations.
Data is collected on a bimanual Dexmate Vega-1 with two 7-DoF arms and two 22-DoF Sharpa Wave dexterous hands (five fingertip tactile sensors per hand). Perception combines a head ZED X Mini stereo camera with two wide-view wrist cameras; teleoperation uses Manus gloves and VIVE trackers routed through the same control pipeline used at deployment. Every episode is a time-aligned bundle at 30 Hz: three RGB streams, bimanual proprioception, SE(3) wrist poses, per-fingertip tactile (a deformation depth map plus a 6-axis wrench for all ten fingertips), and a language instruction — beneath a 300 Hz low-level control thread.
- Personal Care
- Hardware & Tools
- Toys
- Kitchen
- Wrapping & Tape
- Electronics
- Fabric & Cloth
- Clothing
- Containers
- Paper & Writing
Explore the dataset
Browse a 500-trajectory random subset, filter by object and motion primitive, and resample on demand — all in your browser. Click the preview to open the full interactive visualizer.
Open the dataset visualizer →Model & Architecture
T-Rex is built around one idea: contact-rich dexterity needs two clocks running at once. Vision and language tell the robot what to do and roughly how to move, but they are too slow and too coarse to manage the millisecond-scale forces that decide whether an egg cracks, a card slips, or a bulb threads cleanly. T-Rex therefore splits the policy into a low-frequency visuomotor planning stream and a high-frequency tactile refinement stream, fused inside one shared transformer via a Mixture-of-Transformer-Experts backbone with three experts: a latent expert that predicts future visual representations, an action expert that plans a coarse action chunk, and a lightweight tactile expert that adds high-frequency residual corrections. The figure below shows how these experts fit together.
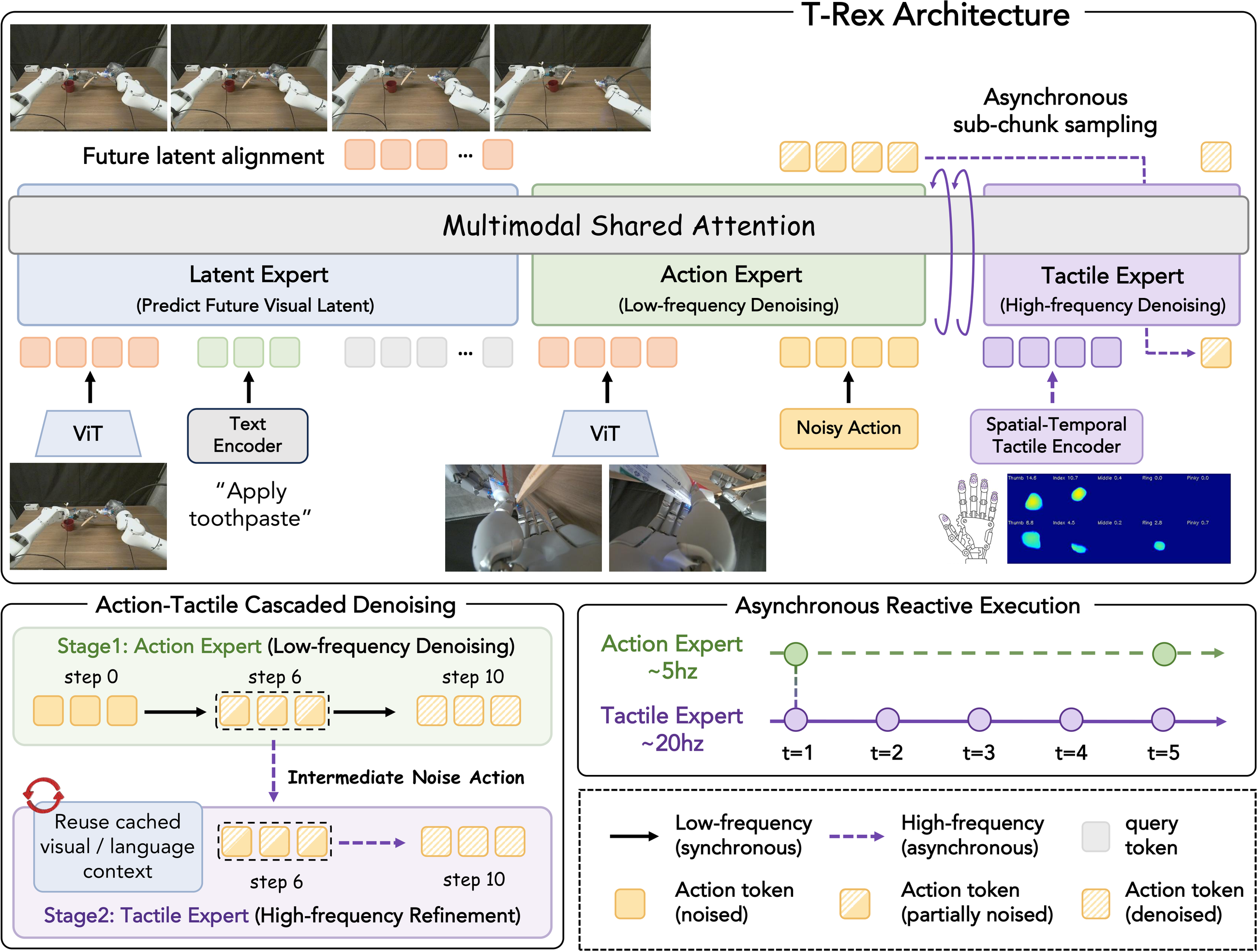
The interaction is an asynchronous cascaded flow-matching scheme. The flow trajectory is split at τ = 0.4: the action expert integrates the upper segment (τ : 1 → 0.4) over 6 steps to produce a coarse plan, whose vision-language context is cached as a frozen snapshot. The tactile expert clones that cache and finishes the lower segment (τ : 0.4 → 0) over just 4 cheap steps, conditioned on live tactile tokens — and re-fires at intra-chunk offsets {0, 4, 8, 12}, four fast tactile ticks per slow visuomotor tick. Because the expensive vision/planning compute is amortized across many fast ticks, per-step cost is dominated by four lightweight tactile steps — fast enough for real closed-loop reaction.
Temporal tactile VQ-VAE encoder
Tactile feedback carries two complementary signals: temporal force dynamics (how contact forces evolve) and spatial contact geometry (edges, slip, shear). T-Rex encodes each separately. A per-finger VQ-VAEcompresses a 16-frame window of raw 6-D force/torque through a 1D temporal convolutional encoder into a 256-D embedding, then vector-quantizes it to a learned codebook (K = 64) — one discrete, drift-robust token per finger. EMA codebook updates with periodic re-seeding prevent collapse, and a magnitude-weighted reconstruction loss keeps the codebook from collapsing onto the dominant no-contact state. The current unquantized force vector is also projected directly to preserve low-latency present-moment information, and a frozen ResNet-derived encoder turns each fingertip’s deformation map into geometry-aware features. Concatenated, these form the tactile tokens the fast expert consumes — it never re-runs the vision tower.
Training recipe
T-Rex is trained in three stages that progressively transfer large-scale human priors into tactile-reactive control. (1) Human egocentric pre-training on 22,889 hours of first-person video gives the latent and action experts broad visuomotor and language priors (no tactile yet). (2) Tactile-grounded mid-training on the 100-hour T-Rex dataset adapts the action expert to robot observations and trains the tactile expert from scratch as a high-frequency refiner, with a delay augmentation that matches the visual/tactile staleness seen at deployment. (3) Skill-specific post-training fine-tunes on ~100 demonstrations per task. An auxiliary future-visual-prediction objective keeps the rapid tactile reflexes grounded in task context.
Demonstrations
Real-world autonomous policy rollouts on the bimanual dexterous platform. Pick a task to watch the policy execute it; click the video to expand it.
Flip Page. “Turn a page of the book from right to left using your right index finger.”
Results
T-Rex is evaluated against six representative dexterous-manipulation and VLA baselines on 12 tactile-reactive tasks spanning three difficulty families: force-sensitive contact, deformation-aware manipulation, and the hardest bimanual force-deformation tasks. Each task is evaluated over 16 randomized trials, with progress rubrics for multi-stage tasks. T-Rex is the top method on every one of the 12 tasks.
T-Rex reaches a 65% macro-average — +30 absolute points over the strongest baseline (EgoScale, 35%), and over 20× the weakest, across all 12 tactile-reactive tasks.
Two findings stand out. First, large-scale pre-training is essential: policies trained from scratch on ~100 demos (ViTacFormer, RDP) collapse, while EgoScale’s egocentric pre-training makes it the strongest baseline. Second, tactile integration must be done right: naively bolting tactile signals onto a pretrained VLA actually hurts (π0.5 + tactile scores below plain π0.5). T-Rex combines large-scale pre-training, tactile-grounded mid-training, and tactile-reactive control to win across the board.
Per-task results
| Method | Flip Page | Transfer Egg | Wipe Plate | Apply Paste | Split Cup | Sort Mahjong | Open Lock | Refill Tablet | Acid-Base | Extract Card | Deal Poker | Screw Bulb | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ViTacFormer | 9 | 0 | 4 | 1 | 4 | 7 | 0 | 0 | 0 | 2 | 2 | 1 | 3 |
| RDP | 12 | 8 | 18 | 2 | 6 | 9 | 2 | 0 | 0 | 1 | 2 | 7 | 6 |
| Tactile-VLA | 38 | 14 | 24 | 0 | 21 | 27 | 8 | 0 | 9 | 4 | 11 | 18 | 15 |
| π0.5 | 36 | 17 | 28 | 13 | 18 | 32 | 5 | 1 | 24 | 8 | 9 | 11 | 17 |
| π0.5 + tactile | 8 | 9 | 27 | 2 | 4 | 14 | 2 | 0 | 7 | 3 | 0 | 0 | 6 |
| EgoScale | 68 | 44 | 34 | 38 | 33 | 36 | 19 | 12 | 43 | 41 | 28 | 18 | 35 |
| T-Rex (Ours) | 96 | 75 | 69 | 66 | 78 | 65 | 47 | 41 | 76 | 70 | 57 | 35 | 65 |
Ablations
Every component earns its place. Removing touch entirely is the most damaging; the temporal VQ-VAE force encoder, the asynchronous cascade, and both training stages each contribute measurably.
Tactile modality & encoding
Removing touch entirely is the most damaging (−23 pts); the temporal VQ-VAE force encoder is what makes touch pay off.
Asynchronous cascaded flow matching
Decoupling low-frequency planning from high-frequency tactile refinement gives a consistent +5 pts.
Training recipe (pre-train × mid-train)
From an 18-pt scratch baseline, tactile-grounded mid-training and human pre-training each help; together they reach the full recipe.
We also sweep the cascaded denoising split step Kslow. An intermediate split is best across all three contact-rich tasks: too small a split leaves the action expert with too few visuomotor priors for the tactile expert to refine, while too large a split starves the tactile expert of capacity to fold in feedback.
Apply Toothpaste
Split Cup
Extract Card
Finally, T-Rex is markedly more data-efficient. With tactile-grounded mid-training (blue), success climbs far faster as post-training demonstrations grow than training from scratch without mid-training (green) — the gap is largest in the low-data regime.
Apply Toothpaste
Split Cup
Extract Card
Failure cases
Six recurring failure modes point to where tactile-reactive dexterity still has headroom:

Limitations & future directions
- Hard, tightly-toleranced long-horizon tasks where good teleoperation is difficult — future work could add reinforcement learning or online refinement beyond behavior cloning.
- Tactile hardware bottlenecks — sensor distortion, calibration drift across devices, and the absence of dense palm sensing for true whole-hand manipulation.
- Toward unified, richer tactile sensing — representations that generalize across heterogeneous sensors, and whole-hand hardware with dense coverage beyond the fingertips.
Conclusion
T-Rex brings large-scale pre-training and high-frequency touch together for contact-rich bimanual manipulation. A Mixture-of-Transformer model combines asynchronous tactile refinement with a temporal tactile VQ-VAE, processing touch at high frequency without slowing the main policy. Trained with human-video pre-training and an open-source 100-hour tactile-synchronized dataset, T-Rex outperforms existing dexterous and tactile-aware VLA baselines by an average of 30% across 12 real-world tactile-reactive tasks while substantially improving data efficiency — a practical recipe for tactile-reactive dexterous control.
Citation
The T-Rex paper is available on arXiv. If you find this work useful, please cite:
@misc{niu2026trextactilereactivedexterousmanipulation,
title={T-Rex: Tactile-Reactive Dexterous Manipulation},
author={Dantong Niu and Zhuoyang Liu and Zekai Wang and Boning Shao and Zhao-Heng Yin and Anirudh Pai and Yuvan Sharma and Stefano Saravalle and Ruijie Zheng and Jing Wang and Ryan Punamiya and Mengda Xu and Yuqi Xie and Yunfan Jiang and Letian Fu and Konstantinos Kallidromitis and Matteo Gioia and Junyi Zhang and Jiaxin Ge and Haiwen Feng and Fabio Galasso and Wei Zhan and David M. Chan and Yutong Bai and Roei Herzig and Jiahui Lei and Fei-Fei Li and Ken Goldberg and Jitendra Malik and Pieter Abbeel and Yuke Zhu and Danfei Xu and Jim and Fan and Trevor Darrell},
year={2026},
eprint={2606.17055},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2606.17055},
}This project page is built on the open-source ENPIRE project-page template — many thanks to its authors.